PostgreSql Two - Plsql 2 (90 Min)
Import Database Here
E:\Software\DB

Cursor
A PL/pgSQL cursor allows you to encapsulate a query and process each individual row at a time.
Typically, you use cursors when you want to divide a large result set into parts and process each part individually. If you process it at once, you may have a memory overflow error.
On top of that, you can develop a function that returns a reference to a cursor. This is an effective way to return a large result set from a function. The caller of the function can process the result set based on the cursor reference.
The following diagram illustrates how to use a cursor in PostgreSQL:
create or replace function get_film_titles(p_year integer)
returns text as $$
declare
titles text default '';
rec_film record;
cur_films cursor(p_year integer)
for select title, release_year
from film
where release_year = p_year;
begin
-- open the cursor
open cur_films(p_year);
loop
-- fetch row into the film
fetch cur_films into rec_film;
-- exit when no more row to fetch
exit when not found;
-- build the output
if rec_film.title like '%ful%' then
titles := titles || ',' || rec_film.title || ':' || rec_film.release_year;
end if;
end loop;
-- close the cursor
close cur_films;
return titles;
end; $$
language plpgsql;
-- Ask to change in refcursor
-----
select get_film_titles(2006);
-----
CREATE TABLE basket_a (
a INT PRIMARY KEY,
fruit_a VARCHAR (100) NOT NULL
);
CREATE TABLE basket_b (
b INT PRIMARY KEY,
fruit_b VARCHAR (100) NOT NULL
);
INSERT INTO basket_a (a, fruit_a)
VALUES
(1, 'Apple'),
(2, 'Orange'),
(3, 'Banana'),
(4, 'Cucumber');
INSERT INTO basket_b (b, fruit_b)
VALUES
(1, 'Orange'),
(2, 'Apple'),
(3, 'Watermelon'),
(4, 'Pear');
SELECT
a,
fruit_a,
b,
fruit_b
FROM
basket_a
INNER JOIN basket_b
ON fruit_a = fruit_b;
SELECT
a,
fruit_a,
b,
fruit_b
FROM
basket_a
LEFT JOIN basket_b
ON fruit_a = fruit_b;
SELECT
a,
fruit_a,
b,
fruit_b
FROM
basket_a
LEFT JOIN basket_b
ON fruit_a = fruit_b
WHERE b IS NULL;
SELECT
a,
fruit_a,
b,
fruit_b
FROM
basket_a
RIGHT JOIN basket_b
ON fruit_a = fruit_b
WHERE a IS NULL;
SELECT
a,
fruit_a,
b,
fruit_b
FROM
basket_a
FULL JOIN basket_b
ON fruit_a = fruit_b
WHERE a IS NULL OR b IS NULL;
SELECT
c.customer_id,
first_name,
amount,
payment_date
FROM
customer c
INNER JOIN payment p
ON p.customer_id = c.customer_id
ORDER BY
payment_date DESC;
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
first_name VARCHAR (255) NOT NULL,
last_name VARCHAR (255) NOT NULL,
manager_id INT,
FOREIGN KEY (manager_id)
REFERENCES employee (employee_id)
);
INSERT INTO employees (
employee_id,
first_name,
last_name,
manager_id
)
VALUES
(1, 'Windy', 'Hays', NULL),
(2, 'Ava', 'Christensen', 1),
(3, 'Hassan', 'Conner', 1),
(4, 'Anna', 'Reeves', 2),
(5, 'Sau', 'Norman', 2),
(6, 'Kelsie', 'Hays', 3),
(7, 'Tory', 'Goff', 3),
(8, 'Salley', 'Lester', 3);
In this employee table, the manager_id column references the employee_id column. The value in the manager_id column shows the manager that the employee directly reports to. When the value in the manager_id column is null, that employee does not report to anyone. In other words, he or she is the top manager.
Comparing the rows with the same table
SELECT
e.first_name || ' ' || e.last_name employees,
m .first_name || ' ' || m .last_name manager
FROM
employees e
LEFT JOIN employees m ON m .employee_id = e.manager_id
ORDER BY manager;
------
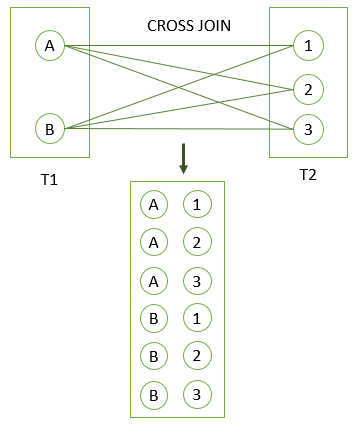
PostgreSQL Cross Join
The following picture illustrates the result of the CROSS JOIN when joining the table T1 to the table T2:
DROP TABLE IF EXISTS T1;
CREATE TABLE T1 (label CHAR(1) PRIMARY KEY);
DROP TABLE IF EXISTS T2;
CREATE TABLE T2 (score INT PRIMARY KEY);
INSERT INTO T1 (label)
VALUES
('A'),
('B');
INSERT INTO T2 (score)
VALUES
(1),
(2),
(3);
SELECT *
FROM T1
CROSS JOIN T2;
NATURAL JOIN
A natural join is a join that creates an implicit join based on the same column names in the joined tables.
Retrieves the forgine key id
DROP TABLE IF EXISTS categories;
CREATE TABLE categories (
category_id serial PRIMARY KEY,
category_name VARCHAR (255) NOT NULL
);
DROP TABLE IF EXISTS products;
CREATE TABLE products (
product_id serial PRIMARY KEY,
product_name VARCHAR (255) NOT NULL,
category_id INT NOT NULL,
FOREIGN KEY (category_id) REFERENCES categories (category_id)
);
INSERT INTO categories (category_name)
VALUES
('Smart Phone'),
('Laptop'),
('Tablet');
INSERT INTO products (product_name, category_id)
VALUES
('iPhone', 1),
('Samsung Galaxy', 1),
('HP Elite', 2),
('Lenovo Thinkpad', 2),
('iPad', 3),
('Kindle Fire', 3);
SELECT * FROM products
NATURAL JOIN categories;
The above statement is equivalent to the following statement that uses the INNER JOIN clause.
SELECT * FROM products
INNER JOIN categories USING (category_id);
It works only if theres is two columns in another Table
CREATE TABLE productss (
product_id serial PRIMARY KEY,
product_name VARCHAR (255) NOT NULL,
category_id INT NOT NULL,
FOREIGN KEY (category_id) REFERENCES categoriess (category_id)
);
INSERT INTO categoriess (category_name,test)
VALUES
('Smart Phone','1'),
('Laptop','22'),
('Tablet','33');
INSERT INTO products (product_name, category_id)
VALUES
('iPhone', 1),
('Samsung Galaxy', 1),
('HP Elite', 2),
('Lenovo Thinkpad', 2),
('iPad', 3),
('Kindle Fire', 3);
SELECT * FROM productss
NATURAL JOIN categoriess
It Won’t Work
It works only if theres is two columns in another Table
--------------------------
Dynamic QUERY
Select * from dynamic(‘ref1’);
Fetch all in “ref1”;
create or replace function dynamic(ref1 refcursor)
RETURNS SETOF refcursor
LANGUAGE 'plpgsql'
COST 100
VOLATILE
ROWS 1000
AS $BODY$
DECLARE
sqlQ VARCHAR;
BEGIN
sqlQ = 'select * from actor';
---RETURN QUERY EXECUTE sqlQ;
open ref1 for
EXECUTE sqlQ;
return next ref1;
END;
$BODY$;
----
CREATE VIEW customer_master AS
SELECT cu.customer_id AS id,
cu.first_name || ' ' || cu.last_name AS name,
a.address,
a.postal_code AS "zip code",
a.phone,
city.city,
country.country,
CASE
WHEN cu.activebool THEN 'active'
ELSE ''
END AS notes,
cu.store_id AS sid
FROM customer cu
INNER JOIN address a USING (address_id)
INNER JOIN city USING (city_id)
INNER JOIN country USING (country_id);
SELECT
*
FROM
customer_master;
-----
update VIEW
CREATE VIEW usa_city AS SELECT
city_id,
city,
country_id
FROM
city
WHERE
country_id = 102
ORDER BY
city;
INSERT INTO usa_city (city, country_id)
VALUES ('Birmingham', 102);
INSERT INTO usa_city (city, country_id)
VALUES ('Cambridge', 102);
SELECT
city_id,
city,
country_id
FROM
city
WHERE
country_id = 102
ORDER BY
city;
-----
Dynamic QUERY
create or replace function dynamic(ref1 refcursor)
RETURNS SETOF refcursor
LANGUAGE 'plpgsql'
COST 100
VOLATILE
ROWS 1000
AS $BODY$
DECLARE
sqlQ VARCHAR;
BEGIN
sqlQ = 'select * from actor';
---RETURN QUERY EXECUTE sqlQ;
open ref1 for
EXECUTE sqlQ;
return next ref1;
END;
$BODY$;
----
CREATE VIEW customer_master AS
SELECT cu.customer_id AS id,
cu.first_name || ' ' || cu.last_name AS name,
a.address,
a.postal_code AS "zip code",
a.phone,
city.city,
country.country,
CASE
WHEN cu.activebool THEN 'active'
ELSE ''
END AS notes,
cu.store_id AS sid
FROM customer cu
INNER JOIN address a USING (address_id)
INNER JOIN city USING (city_id)
INNER JOIN country USING (country_id);
SELECT
*
FROM
customer_master;
-----
update VIEW
CREATE VIEW usa_city AS SELECT
city_id,
city,
country_id
FROM
city
WHERE
country_id = 102
ORDER BY
city;
INSERT INTO usa_city (city, country_id)
VALUES ('Birmingham', 102);
INSERT INTO usa_city (city, country_id)
VALUES ('Cambridge', 102);
SELECT
city_id,
city,
country_id
FROM
city
WHERE
country_id = 102
ORDER BY
city;
----------------------------------------
Group by and Having
SELECT
customer_id,
SUM (amount)
FROM
payment
GROUP BY
customer_id;
We cannot use where with aggregate function
SELECT
customer_id,
SUM (amount)
FROM
payment
GROUP BY
customer_id
HAVING
SUM (amount) > 200;
----------------
Union
Joins two select queries with distinct values
DROP TABLE IF EXISTS top_rated_films;
CREATE TABLE top_rated_films(
title VARCHAR NOT NULL,
release_year SMALLINT
);
DROP TABLE IF EXISTS most_popular_films;
CREATE TABLE most_popular_films(
title VARCHAR NOT NULL,
release_year SMALLINT
);
INSERT INTO
top_rated_films(title,release_year)
VALUES
('The Shawshank Redemption',1994),
('The Godfather',1972),
('12 Angry Men',1957);
INSERT INTO
most_popular_films(title,release_year)
VALUES
('An American Pickle',2020),
('The Godfather',1972),
('Greyhound',2020);
SELECT * FROM top_rated_films
UNION
SELECT * FROM most_popular_films;
In this example, the duplicate row is retained in the result set.
SELECT * FROM top_rated_films
UNION ALL
SELECT * FROM most_popular_films;
SELECT * FROM top_rated_films
UNION ALL
SELECT * FROM most_popular_films
ORDER BY title;
INTERSECT
Like the UNION and EXCEPT operators, the PostgreSQL INTERSECT operator combines result sets of two or more SELECT statements into a single result set.

SELECT *
FROM most_popular_films
INTERSECT
SELECT *
FROM top_rated_films;
EXCEPT
SELECT * FROM top_rated_films
EXCEPT
SELECT * FROM most_popular_films
ORDER BY title;
GROUPING SETS -
A grouping set is a set of columns by which you group by using the GROUP BY clause.
A grouping set is denoted by a comma-separated list of columns placed inside parentheses:
DROP TABLE IF EXISTS sales;
CREATE TABLE sales (
brand VARCHAR NOT NULL,
segment VARCHAR NOT NULL,
quantity INT NOT NULL,
PRIMARY KEY (brand, segment)
);
INSERT INTO sales (brand, segment, quantity)
VALUES
('ABC', 'Premium', 100),
('ABC', 'Basic', 200),
('XYZ', 'Premium', 100),
('XYZ', 'Basic', 300);
Here () means have null in brand and segment ,
Here we can do multiple kind of group by at a time
SELECT
brand,
segment,
SUM (quantity)
FROM
sales
GROUP BY
GROUPING SETS (
(brand, segment),
(brand),
(segment),
()
);
Sub Query
SELECT
film_id,
title,
rental_rate
FROM
film
WHERE
rental_rate > (
SELECT
AVG (rental_rate)
FROM
film
);
Any
SELECT
title,
category_id
FROM
film
INNER JOIN film_category
USING(film_id)
WHERE
category_id = ANY(
SELECT
category_id
FROM
category
WHERE
NAME = 'Action'
OR NAME = 'Drama'
);
Overview of the PostgreSQL ALL operator
The PostgreSQL ALL operator allows you to query data by comparing a value with a list of values returned by a subquery.
The following illustrates the syntax of the ALL operator:
comparison_operator ALL (subquery)
Code language: SQL (Structured Query Language) (sql)
In this syntax:
The ALL operator must be preceded by a comparison operator such as equal (=), not equal (!=), greater than (>), greater than or equal to (>=), less than (<), and less than or equal to (<=).
The ALL operator must be followed by a subquery which also must be surrounded by the parentheses.
To find all films whose lengths are greater than the list of the average lengths above, you use the ALL and greater than operator (>) as follows:
SELECT
film_id,
title,
length
FROM
film
WHERE
length > ALL (
SELECT
ROUND(AVG (length),2)
FROM
film
GROUP BY
rating
)
ORDER BY
length;
CTE
PostgreSQL CTE advantages
The following are some advantages of using common table expressions or CTEs:
Improve the readability of complex queries. You use CTEs to organize complex queries in a more organized and readable manner.
Ability to create recursive queries. Recursive queries are queries that reference themselves. The recursive queries come in handy when you want to query hierarchical data such as organization chart or bill of materials.
Use in conjunction with window functions. You can use CTEs in conjunction with window functions to create an initial result set and use another select statement to further process this result set.
WITH cte_film AS (
SELECT
film_id,
title,
(CASE
WHEN length < 30 THEN 'Short'
WHEN length < 90 THEN 'Medium'
ELSE 'Long'
END) length
FROM
film
)
SELECT
film_id,
title,
length
FROM
cte_film
WHERE
length = 'Long'
ORDER BY
title;
Joining a CTE with a table example
In the following example, we will use the rental and staff tables:
The following statement illustrates how to join a CTE with a table:
WITH cte_rental AS (
SELECT staff_id,
COUNT(rental_id) rental_count
FROM rental
GROUP BY staff_id
)
SELECT s.staff_id,
first_name,
last_name,
rental_count
FROM staff s
INNER JOIN cte_rental USING (staff_id);
Using CTE with a window function example
The following statement illustrates how to use the CTE with the RANK() window function:
WITH cte_film AS (
SELECT film_id,
title,
rating,
length,
RANK() OVER (
PARTITION BY rating
ORDER BY length DESC)
length_rank
FROM
film
)
SELECT *
FROM cte_film
WHERE length_rank = 1;
PostgreSQL Upsert Using INSERT ON CONFLICT statement
In relational databases, the term upsert is referred to as merge. The idea is that when you insert a new row into the table, PostgreSQL will update the row if it already exists, otherwise, it will insert the new row. That is why we call the action is upsert (the combination of update or insert).
DROP TABLE IF EXISTS customers;
CREATE TABLE customers (
customer_id serial PRIMARY KEY,
name VARCHAR UNIQUE,
email VARCHAR NOT NULL,
active bool NOT NULL DEFAULT TRUE
);
INSERT INTO
customers (name, email)
VALUES
('IBM', 'contact@ibm.com'),
('Microsoft', 'contact@microsoft.com'),
('Intel', 'contact@intel.com');
INSERT INTO customers (name, email)
VALUES('Microsoft','hotline@microsoft.com')
ON CONFLICT (name)
DO
UPDATE SET email = EXCLUDED.email || ';' || customers.email;
select * from customers
DROP TABLE IF EXISTS accounts;
CREATE TABLE accounts (
id INT GENERATED BY DEFAULT AS IDENTITY,
name VARCHAR(100) NOT NULL,
balance DEC(15,2) NOT NULL,
PRIMARY KEY(id)
);
INSERT INTO accounts(name,balance)
VALUES('Bob',10000);
-- start a transaction
BEGIN;
-- deduct 1000 from account 1
UPDATE accounts
SET balance = balance - 1000
WHERE id = 1;
-- add 1000 to account 2
UPDATE accounts
SET balance = balance + 1000
WHERE id = 2;
-- select the data from accounts
SELECT id, name, balance
FROM accounts;
-- commit the transaction
COMMIT;
BEGIN;
UPDATE accounts
SET balance = balance - 1500
WHERE id = 1;
UPDATE accounts
SET balance = balance + 1500
WHERE id = 3;
ROLLBACK;
SELECT
id,
name,
balance
FROM
accounts;

Comments
Post a Comment