SQL Concepts
Why This Blog
- To Know Some Unknown Concepts Shortly And In a Single Page
SQL Concepts





What is Normalization?
https://www.youtube.com/watch?v=ABwD8IYByfk
- NORMALIZATION is a database design technique that organizes tables in a manner that reduces redundancy and dependency of data.
- Normalization divides larger tables into smaller tables and links them using relationships.
- The purpose of Normalization is to eliminate redundant (useless) data and ensure data is stored logically.
Rules for First Normal Form
The first normal form expects you to follow a few simple rules while designing your database, and they are:
Rule 1: Single Valued
- Each column of your table should be single valued which means they should not contain multiple values


Rule 2: Attribute Domain should not change
- In each column the values stored must be of the same kind or type
- avoid partial dependency
- all columns of the table should depend on the primary key only
Rule 3: Unique name for Attributes/Columns
- This rule expects that each column in a table should have a unique name
Rule 4: Order doesn't matters
- This rule says that the order in which you store the data in your table doesn't matter.
Rules for Second Normal Form
- The table should be in the First Normal Form.
- There should be no Partial Dependency.
What is Partial Dependency?
Now that we know what dependency is, we are in a better state to understand what partial dependency is.
For a simple table like Student, a single column like
student_id can uniquely identfy all the records in a table.
But this is not true all the time. So now let's extend our example to see if more than 1 column together can act as a primary key.
Let's create another table for Subject, which will have
subject_id and subject_name fields and subject_id will be the primary key.| subject_id | subject_name |
|---|---|
| 1 | Java |
| 2 | C++ |
Requirements for Third Normal Form
For a table to be in the third normal form,
- It should be in the Second Normal form.
- And it should not have Transitive Dependency.
What is Transitive Dependency?
- The column which depends on non- primary key . that we need to separate in a new table

How to remove Transitive Dependency?
Again the solution is very simple. Take out the columns
exam_name and total_marks from Score table and put them in an Exam table and use the exam_id wherever required.Score Table: In 3rd Normal Form
| score_id | student_id | subject_id | marks | exam_id |
|---|---|---|---|---|
The new Exam table
| exam_id | exam_name | total_marks |
|---|---|---|
| 1 | Workshop | 200 |
| 2 | Mains | 70 |
Rules for BCNF
For a table to satisfy the Boyce-Codd Normal Form, it should satisfy the following two conditions:
- It should be in the Third Normal Form.
- And, for any dependency A → B, A should be a super key.
What is the difference between ExecuteScalar, ExecuteReader and ExecuteNonQuery?
ExecuteScalar() only returns the value from the first column of the first row of your query.
ExecuteReader() returns an object that can iterate over the entire result set.
- It is very useful to use with aggregate functions like Count(*) or Sum() etc. When compare to ExecuteReader() , ExecuteScalar() uses fewer System resources.
ExecuteNonQuery() does not return data at all: only the number of rows affected by an insert, update, or delete
It is very useful to use with aggregate functions like Count(*) or Sum() etc. When compare to ExecuteReader() , ExecuteScalar() uses fewer System resources.
SqlDataReader
- To Read the specific column from the sql command result set
CHAR & VARCHAR & NVARCHARCHAR
-Talking about the CHAR data type:
-It is a fixed length data type
-Occupies 1 byte of space for each character
VARCHAR
-It is a variable length data type
-Occupies 1 byte of space for each character
NVARCHAR
-Is a fixed length data type
-Occupies 2 bytes of space for each character
-Talking about the CHAR data type:
-It is a fixed length data type
-Occupies 1 byte of space for each character
VARCHAR
-It is a variable length data type
-Occupies 1 byte of space for each character
NVARCHAR
-Is a fixed length data type
-Occupies 2 bytes of space for each character
Various Types of Tables
1. User Tables (Regular Tables)
- Create TABLE [dbo].[Employee]
- (
- [EmpID] [int] NULL,
- [EmpName] [varchar](30) NULL,
- [EmpSalary] [int] NULL
- )
2. Local Temporary Tables
The following is a sample of creating a local temporary table:
- create table #table_name
- (
- column_name varchar(20),
- column_no int
- )
- Local temporary tables are temporary tables that are available only to the session that created them.
- They are specified with the prefix #
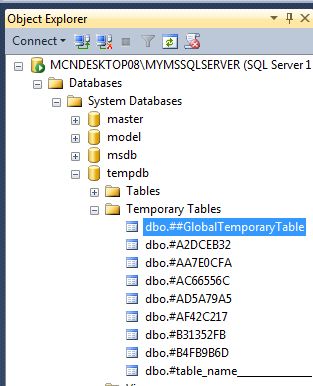
3. Global Temporary Tables
- Global temporary tables are also stored in tempdb
- Global temporary tables are temporary tables that are available to all sessions and all users
- They are dropped automatically when the last session using the temporary table has completed
- They are specified with the prefix ##, for example ##table_name
- create table ##GlobalTemporaryTable
- (
- column_name varchar(20),
- column_no int
- )
- Whenever we create a temporary table, it goes to the Temporary folder of the tempdb database. tempdb -> temporary tables
4. Creation of Table with the Help of Another Table
Suppose you create a table named employee table (like the above table). The following is the sample data for the employee Table:

Now we want to create a table which is exactly the copy of a given table; then we can also use the following SQL Query:
- SELECT * into studentCopy FROM employee
Now using a select statement with the table named studentCopy:
- SELECT * FROM studentCopy
Output

5. Table Variable
Temporary Tables are physically created in the tempdb database. These tables act as the normal table and also can have constraints, index like normal tables. Table Variable acts like a variable and exists for a particular batch of query execution. It gets dropped once it comes out of batch
Table variables are alternatives to temporary tables which store a set of records. The syntax of a table variable is shown below
Inserting a value into the table variable:
- Declare @Employee Table
- (
- [EmpID] [int] NULL,
- [EmpName] [varchar](30) NULL,
- [EmpSalary] [int] NULL
- )
- INSERT INTO @Employee (EmpID, EmpName, EmpSalary) values (1, 'Rohatash', 1000)
- Select * from @Employee
User-Defined Table Type
- CREATE PROCEDURE Sp_InsertMyUDTableByMyUDTableType
- @MyUDTableType MyUDTableType READONLY
- AS
- BEGIN
- INSERT INTO MyUDTable
- SELECT * FROM @MyUDTableType
- END
- DECLARE @MyUserDTableType MyUDTableType
- INSERT INTO @MyUserDTableType VALUES (1, 'Mark', 'Male')
- INSERT INTO @MyUserDTableType VALUES (2, 'Mary', 'Female')
- INSERT INTO @MyUserDTableType VALUES (3, 'John', 'Male')
- INSERT INTO @MyUserDTableType VALUES (4, 'Sara', 'Female')
- EXECUTE Sp_InsertMyUDTableByMyUDTableType @MyUserDTableType
Stack overflow challenges
Is PostgreSQL case-insensitive
In PostgreSQL unquoted names are case-insensitive. Thus
SELECT * FROM hello and SELECT * FROM HELLO are equivalent.
However, quoted names are case-sensitive.
SELECT * FROM "hello" is not equivalent to SELECT * FROM "HELLO".
To make a "bridge" between quoted names and unquoted names, unquoted names are implicitly lowercased, thus
hello, HELLO and HeLLo are equivalent to "hello", but not to "HELLO" or "HeLLo" (OOPS!).
Thus, when creating entities (tables, views, procedures, etc) in PostgreSQL, you should specify them either unquoted, or quoted-but-lowercased.
OFFSET FETCH
The following illustrates the
OFFSET and FETCH clauses:
To skip the first 10 products and return the rest, you use the OFFSET clause as shown in the following statement:
SELECT
product_name,
list_price
FROM
production.products
ORDER BY
list_price,
product_name
OFFSET 10 ROWS;
To skip the first 10 products and select the next 10 products, you use both OFFSET and FETCH clauses as follows:
SELECT
product_name,
list_price
FROM
production.products
ORDER BY
list_price,
product_name
OFFSET 10 ROWS
FETCH NEXT 10 ROWS ONLY;
Procedure For Pagging
CREATE PROCEDURE Pagination_Test_1
@PageNumber INT = 1,
@PageSize INT = 100
AS
BEGIN
SET NOCOUNT ON;
SELECT
product_name,
list_price
FROM
production.products
ORDER BY
list_price,
product_name
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY OPTION (RECOMPILE);
END
GO
SELECT TOP
The SELECT TOP clause allows you to limit the number of rows or percentage of
rows returned in a query result set.
SELECT TOP 10
product_name,
list_price
FROM
production.products
ORDER BY
list_price DESC;
2) Using TOP to return a percentage of rows
The following example uses PERCENT to specify the number of products returned in the result set. The production.products table has 321 rows, therefore, one percent of 321 is a fraction value ( 3.21), SQL Server rounds it up to the next whole number which is four ( 4) in this case.
SELECT TOP 1 PERCENT
product_name,
list_price
FROM
production.products
ORDER BY
list_price DESC;
LIKE
The following example finds the customers whose last name starts with the letter z:
SELECT
customer_id,
first_name,
last_name
FROM
sales.customers
WHERE
last_name LIKE 'z%'
ORDER BY
first_name;
The following example returns the customers whose last name ends with the string er:
SELECT
customer_id,
first_name,
last_name
FROM
sales.customers
WHERE
last_name LIKE '%er'
ORDER BY
first_name;
The following statement retrieves the customers whose last name starts with the letter t and ends with the letter s:
SELECT
customer_id,
first_name,
last_name
FROM
sales.customers
WHERE
last_name LIKE 't%s'
ORDER BY
first_name;
For example, the following query finds the customers where the first character
in the last name is the letter in the range A through C:
SELECT
customer_id,
first_name,
last_name
FROM
sales.customers
WHERE
last_name LIKE '[A-C]%'
ORDER BY
first_name;
coalesce :
LEFT JOIN
The LEFT JOIN clause allows you to query data from multiple tables. It returns all rows from the left table and the matching rows from the right table. If no matching rows found in the right table, NULL are used.
SAME AS OPPOSITE FOR RIGHT JOIN
The
CROSS JOIN joined every row from the first table (T1) with every row from the second table (T2). In other words, the cross join returns a Cartesian product of rows from both tables.
Unlike the
INNER JOIN or LEFT JOIN, the cross join does not establish a relationship between the joined tables.
Suppose the T1 table contains three rows 1, 2, and 3 and the T2 table contains three rows A, B, and C.
The
CROSS JOIN gets a row from the first table (T1) and then creates a new row for every row in the second table (T2). It then does the same for the next row for in the first table (T1) and so on.
ISNULL
There are two ways to replace NULL with blank values in SQL Server, function ISNULL() and COALESCE(). Both functions replace the value you provide when the argument is NULL e.g. ISNULL(column, '') will return empty String if the column value is NULL
Group By
The GROUP BY statement groups rows that have the same values into summary rows, like "find the number of customers in each country".
The following SQL statement lists the number of customers in each country:
SELECT COUNT(CustomerID), Country
FROM Customers
GROUP BY Country;
Having
The HAVING clause was added to SQL because the WHERE keyword could not be used with aggregate functions.
Sub Query
ex: select 2nd highest salary
select max(customer_id) from sales.customers
where customer_id < (select max(customer_id) from sales.customers)
Correlated Subquery
A correlated subquery is a subquery that uses the values of the outer query.
In other words, it depends on the outer query for its values.
Because of this dependency, a correlated subquery cannot be executed
independently as a simple subquery.
The following example finds the products whose list price is equal to the
maximum list price of its category.
SELECT
product_name,
list_price,
category_id
FROM
production.products p1
WHERE
list_price IN (
SELECT
MAX (p2.list_price)
FROM
production.products p2
WHERE
p2.category_id = p1.category_id
GROUP BY
p2.category_id
)
ORDER BY
category_id,
product_name;
Union
SQL Server
UNION is one of the set operations that allows you to combine results of two SELECT statements into a single result set which includes all the rows that belongs to the SELECT statements in the union.
The following picture illustrates the main difference between
UNION and JOIN: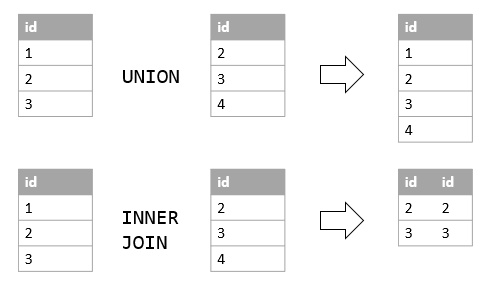
SELECT
first_name,
last_name
FROM
sales.staffs
UNION
SELECT
first_name,
last_name
FROM
sales.customers;
Note:To include the duplicate row, you use the UNION ALL as shown in the following query:
INTERSECT
Union - Returns All Distinct Values
Intersect - Returns Only Common Values like inner join but it will return in
single row
SELECT
city
FROM
sales.customers
Intersect
SELECT
city
FROM
sales.stores
ORDER BY
city;
The following picture illustrates the 
INTERSECT operation:
EXCEPT
The SQL Server EXCEPT compares the result sets of two queries and
returns the distinct rows from the first query that are not output
by the second query. In other words, the EXCEPT subtracts the result
set of a query from another.
SELECT
product_id
FROM
production.products
EXCEPT
SELECT
product_id
FROM
sales.order_items;
The following picture shows the
EXCEPT operation of the two result sets T1 and T2:
CTE
- Common Table Expression
- It is a temporary named result set
- That allows you to make execution for curd operations
Why Need CTE
-Create a recursive query.
-Use the CTE's resultset more than once in your query.
-Promote clarity in your query by reducing large chunks of identical subqueries.
- Create a recursive query. For more information, see Recursive Queries Using
Common Table Expressions.
-Substitute for a view when the general use of a view is not required; that
is, you do not have to store the definition in metadata.
- Enable grouping by a column that is derived from a scalar subselect,
or a function that is either not deterministic or has external access.
- Reference the resulting table multiple times in the same statement.
Delete Duplicate Values WIth CTE
WITH cte_t as (
SELECT
contact_id,
first_name,
last_name,
email,
ROW_NUMBER() OVER (
PARTITION BY
first_name,
last_name,
email
ORDER BY
first_name,
last_name,
email
) row_num
FROM
sales.contacts
)
delete from cte_t where row_num >1;
sql insert return identity column.
Insert into TBL (Name, UserName, Password) Output Inserted.IdentityColumnName
View
- To Save a Select Query and Executing it later.
- we can make it with create view query
- View do not store data except indexed views
Eg
CREATE VIEW sales.product_info
AS
SELECT
product_name,
brand_name,
list_price
FROM
production.products p
INNER JOIN production.brands b
ON b.brand_id = p.brand_id;
- Is Views are Updatable
Yes, they are updatable but not always. Views can be updated under followings:
- If the view consists of the primary key of the table based on which the view has been created.
- If the view is defined based on one and only one table.
- If the view has not been defined using groups and aggregate functions.
- If the view does not have any distinct clause in its definition.
- If the view that is supposed to be updated is based on another view, the later should be updatable.
- If the definition of the view does not have any sub queries.
Clustered Index
- A Table should Have one one clustered Index
- It stores values in asc order
- Create clustered index inx_name ON tbl(Gender)
- Or Create Table tbl(id int primary key)
Non - Clustered Index
- Table can have more than one non clustered index
- See the below image when we create non clustered index on name it will collects
all names and it row address , same as for all non - clustered index.
- Create nonclustered index inx_name ON tbl(Gender)
- when you insert, update, or delete rows from the table, SQL Server needs to update the associated non-clustered index

unique index
- It won't allow any duplicate values
- A unique index may consist of one or many columns
- A unique index can be clustered or non-clustered.
CREATE UNIQUE INDEX index_name
ON table_name(column_list);
|
DROP INDEX
DROP INDEX [IF EXISTS] index_name
ON table_name;
Filtered indexes
- A filtered index is a nonclustered index with a predicate that allows you to specify which rows should be added to the index.
- filtered indexes reduce the maintenance cost
- filtered indexes can help you save spaces especially when the index key columns are sparse. Sparse columns are the ones that have many NULL values.
CREATE INDEX index_name
ON table_name(column_list)
WHERE predicate;
|
This statement creates a filtered index for the
phone column of the sales.customers table:
1
2
3
|
CREATE INDEX ix_cust_phone
ON sales.customers(phone)
WHERE phone IS NOT NULL;
|
The following query finds the customer whose phone number is
(281) 363-3309:
Here is the estimated execution plan:

indexes on computed columns
- SOON
user-defined functions
- user-defined functions including scalar-valued functions which return a single value and table-valued function which return rows of data.
- Reusable
- Readable & To Optimized Query
What are scalar functions
- SQL Server scalar function takes one or more parameters and returns a single value.
- The scalar functions help you simplify your code. For example, you may have a complex calculation that appears in many queries. Instead of including the formula in every query, you can create a scalar function that encapsulates the formula and uses it in the queries
Before U should know abt DEC()
SQL — DEC() Function
The DEC() function converts a binary string argument into a numeric value. The string argument is treated as a signed binary integer. A null string argument, DEC(''), will return 0.
The following shows the syntax of the
DECIMAL data type:
In this syntax:
- (P - First Digit Length, S - Second Digit Length)
- p is the precision which is the maximum total number of decimal digits that will be stored, both to the left and to the right of the decimal point. The precision has a range from 1 to 38. The default precision is 38.
- s is the scale which is the number of decimal digits that will be stored to the right of the decimal point. The scale has a range from 0 to p (precision). The scale can be specified only if the precision is specified. By default, the scale is zero.
Back to Scalar Function
The following example creates a function that calculates the net sales based on the quantity, list price, and discount:
CREATE FUNCTION sales.udfNetSale(
@quantity INT,
@list_price DEC(10,2),
@discount DEC(4,2)
)
RETURNS DEC(10,2)
AS
BEGIN
RETURN @quantity * @list_price * (1 - @discount);
END;
|
After creating the scalar function, you can find it under Programmability > Functions > Scalar-valued Functions as shown in the following picture:

Calling a scalar function
You call a scalar function like a built-in function. For example, the following statement demonstrates how to call the
udfNetSale function:
Here is the output:
What are table variables
- Table variables are kind of variables that allow you to hold rows of data, which are similar to a temporary tables.
- If you define a table variable in a stored procedure or user-defined function, the table variable will no longer exist after the stored procedure or user-defined function exits.
-Similar to the temporary table, the table variables do live in the
tempdb database, not in the memory.
Note that you need to execute the whole batch or you will get an error:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
DECLARE @product_table TABLE (
product_name VARCHAR(MAX) NOT NULL,
brand_id INT NOT NULL,
list_price DEC(11,2) NOT NULL
);
INSERT INTO @product_table
SELECT
product_name,
brand_id,
list_price
FROM
production.products
WHERE
category_id = 1;
SELECT
*
FROM
@product_table;
GO
|
What is a table-valued function in SQL Server
Creating a table-valued function
The following statement example creates a table-valued function that returns a list of products including product name, model year and the list price for a specific model year:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
CREATE FUNCTION udfProductInYear (
@model_year INT
)
RETURNS TABLE
AS
RETURN
SELECT
product_name,
model_year,
list_price
FROM
production.products
WHERE
model_year = @model_year;
|
Executing a table-valued function
To execute a table-valued function, you use it in the
FROM clause of the SELECT statement: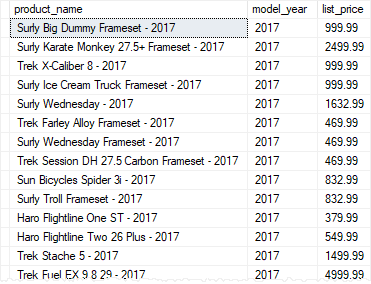
In this example, we selected the products whose model year is
2017.
You can also specify which columns to be returned from the table-valued function as follows:
Here is the partial output:

To drop the sales.udf_get_discount_amount function, you use the following statement:
1
DROP FUNCTION IF EXISTS sales.udf_get_discount_amount;
To drop the
sales.udf_get_discount_amount function, you use the following statement:
1
|
DROP FUNCTION IF EXISTS sales.udf_get_discount_amount;
|
Stored Procedure
- stored procedure groups one or more Transact-SQL statements into a unit.
- When a stored procedure is called at the first time, SQL Server creates an execution plan and stores it in the plan cache
- In the subsequent executions of the stored procedure, SQL Server reuses the plan
- so that the stored procedure can execute very fast with reliable performance
Creating a stored procedure with multiple parameters
CREATE PROCEDURE uspFindProducts(
@min_list_price AS DECIMAL
,@max_list_price AS DECIMAL
)
AS
BEGIN
SELECT
product_name,
list_price
FROM
production.products
WHERE
list_price >= @min_list_price AND
list_price <= @max_list_price
ORDER BY
list_price;
END;
|
Executing
|
OR
EXECUTE uspFindProducts 900, 1000;
|
Declaring a variable
DECLARE @model_year AS SMALLINT;
|
output parameters
- O/P Param is a parameter which is returns values into that variable .
@@ROWCOUNT (Transact-SQL)
Returns the number of rows affected by the last statement.
stored procedure finds products by model year and returns the number of products via the
@product_count output parameter:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
CREATE PROCEDURE uspFindProductByModel (
@model_year SMALLINT,
@product_count INT OUTPUT
) AS
BEGIN
SELECT
product_name,
list_price
FROM
production.products
WHERE
model_year = @model_year;
SELECT @product_count = @@ROWCOUNT;
END;
|
Calling stored procedures with output parameters
- - First, declare variables to hold the value returned by the output parameters
- - Second, use these variables in the stored procedure call.
DECLARE @count INT;
EXEC uspFindProductByModel
@model_year = 2018,
@product_count = @count OUTPUT;
SELECT @count AS 'Number of products found';
|
What is a database cursor
- Database cursor is a object that enables traversal over the rows of result set( From the select query)
- It allows us to filter rows returned by the query.
Cursors in SQL
- It is a database object to retrieve data from a result set
- it can hold more than one row, but can process only one row at a time
There are the following two types of Cursors:
Implicit Cursor
Explicit Cursor
Implicit Cursor
These types of cursors are generated and used by the system during the manipulation of a DML query (INSERT, UPDATE and DELETE).
Explicit Cursor
-This type of cursor is generated by the user using a SELECT command. An explicit cursor contains more than one row, but only one row can be processed at a time
-An explicit cursor uses a pointer that holds the record of a row. After fetching a row, the cursor pointer moves to the next row
Main components of Cursors
Each cursor contains the followings 5 parts,
Declare Cursor: In this part we declare variables and return a set of values.
Open: This is the entering part of the cursor.
Fetch: Used to retrieve the data row by row from a cursor.
Close: This is an exit part of the cursor and used to close a cursor.
Deallocate: In this part we delete the cursor definition and release all the system resources associated with the cursor.
Cursor Scope
Microsoft SQL Server supports the GLOBAL and LOCAL keywords on the DECLARE CURSOR statement to define the scope of the cursor name.
GLOBAL - specifies that the cursor name is global to the connection.
LOCAL - specifies that the cursor name is local to the Stored Procedure, trigger or query that holds the cursor.
Cursors in SQL
- It is a database object to retrieve data from a result set
- it can hold more than one row, but can process only one row at a time
There are the following two types of Cursors:
Implicit Cursor
Explicit Cursor
Implicit Cursor
These types of cursors are generated and used by the system during the manipulation of a DML query (INSERT, UPDATE and DELETE).
Explicit Cursor
-This type of cursor is generated by the user using a SELECT command. An explicit cursor contains more than one row, but only one row can be processed at a time
-An explicit cursor uses a pointer that holds the record of a row. After fetching a row, the cursor pointer moves to the next row
Main components of Cursors
Each cursor contains the followings 5 parts,
Declare Cursor: In this part we declare variables and return a set of values.
Open: This is the entering part of the cursor.
Fetch: Used to retrieve the data row by row from a cursor.
Close: This is an exit part of the cursor and used to close a cursor.
Deallocate: In this part we delete the cursor definition and release all the system resources associated with the cursor.
Cursor Scope
Microsoft SQL Server supports the GLOBAL and LOCAL keywords on the DECLARE CURSOR statement to define the scope of the cursor name.
GLOBAL - specifies that the cursor name is global to the connection.
LOCAL - specifies that the cursor name is local to the Stored Procedure, trigger or query that holds the cursor.
STATIC CURSOR
A static cursor populates the result set during cursor creation and the query result is cached for the lifetime of the cursor. A static cursor can move forward and backward.
FAST_FORWARD
This is the default type of cursor. It is identical to the static except that you can only scroll forward.
DYNAMIC
In a dynamic cursor, additions and deletions are visible for others in the data source while the cursor is open.
KEYSET
This is similar to a dynamic cursor except we can't see records others add.
If another user deletes a record, it is inaccessible from our record set.
A static cursor populates the result set during cursor creation and the query result is cached for the lifetime of the cursor. A static cursor can move forward and backward.
FAST_FORWARD
This is the default type of cursor. It is identical to the static except that you can only scroll forward.
DYNAMIC
In a dynamic cursor, additions and deletions are visible for others in the data source while the cursor is open.
KEYSET
This is similar to a dynamic cursor except we can't see records others add.
If another user deletes a record, it is inaccessible from our record set.
SQL Server cursor example
DECLARE
@product_name VARCHAR(MAX),
@list_price DECIMAL;
DECLARE cursor_product CURSOR
FOR SELECT
product_name,
list_price
FROM
production.products;
|
Next, open the cursor:
1
|
OPEN cursor_product;
|
Then, fetch each row from the cursor and print out the product name and list price:
After that, close the cursor.
Finally, deallocate the cursor to release it.
1
|
DEALLOCATE cursor_product;
|
SQL Server TRY CATCH overview
- The
TRY CATCH construct allows you to gracefully handle exceptions in SQL Server
The CATCH block functions
ERROR_LINE()returns the line number on which the exception occurred.ERROR_MESSAGE()returns the complete text of the generated error message.ERROR_PROCEDURE()returns the name of the stored procedure or trigger where the error occurred.ERROR_NUMBER()returns the number of the error that occurred.ERROR_SEVERITY()returns the severity level of the error that occurred.ERROR_STATE()returns the state number of the error that occurred.
SQL Server THROW statement overview
The
THROW statement raises an exception and transfers execution to a CATCH block of a TRY CATCH construct.
The following illustrates the syntax of the
THROW statement:
1
2
3
|
THROW [ error_number ,
message ,
state ];
|
Dynamic SQL
For example, you can use the dynamic SQL to create a stored procedure that queries data against a table whose name is not known until runtime
EXEC sp_executesql N'SELECT * FROM production.products';
|
SQL Server dynamic SQL and stored procedures
The following statement calls the
usp_query stored procedure to return all rows from the production.brands table:
1
|
EXEC usp_query 'production.brands';
|
Triggers
SQL Server triggers are special stored procedures that are executed automatically in response to the database object, database, and server events
SQL Server provides three type of triggers
- Data manipulation language ( DML ) triggers. are invoked automatically in response to
INSERT, UPDATE, and DELETE events against tables.
- Data definition language (DDL) triggers which fire in response to
CREATE, ALTER, and DROP statements
- Logon triggers which fire in response to
LOGON events
Introduction to SQL Server CREATE TRIGGER statement
The following illustrates the syntax of the
CREATE TRIGGER statement:
1
2
3
4
5
6
|
CREATE TRIGGER [schema_name.]trigger_name
ON table_name
AFTER {[INSERT],[UPDATE],[DELETE]}
[NOT FOR REPLICATION]
AS
{sql_statements}
|
The following put all parts together:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
CREATE TRIGGER production.trg_product_audit
ON production.products
AFTER INSERT, DELETE
AS
BEGIN
SET NOCOUNT ON;
INSERT INTO production.product_audits(
product_id,
product_name,
brand_id,
category_id,
model_year,
list_price,
updated_at,
operation
)
SELECT
i.product_id,
product_name,
brand_id,
category_id,
model_year,
i.list_price,
GETDATE(),
'INS'
FROM
inserted i
UNION ALL
SELECT
d.product_id,
product_name,
brand_id,
category_id,
model_year,
d.list_price,
GETDATE(),
'DEL'
FROM
deleted d;
END
|
INSTEAD OF trigger
- SOON

Comments
Post a Comment