The INTERSECT operator is a set operator that returns distinct rows of two or more result sets from SELECT statements.
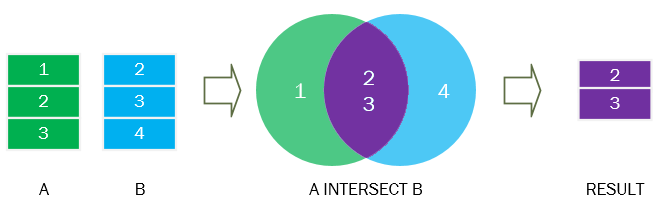
Suppose, we have two tables: A(1,2) and B(2,3).
The following picture illustrates the intersection of A & B tables.
The purple section is the intersection of the green and blue result sets.
Like the UNION operator, the INTERSECT operator removes the duplicate rows from the final result set.
To use the INTERSECT operator, the columns of the SELECT statements must follow the rules:
The data types of columns must be compatible.
The number of columns and their orders in the SELECT statements must be the same.
SQL INTERSECT with ORDER BY example
To sort the result set returned by the INTERSECT operator, you place the ORDER BY clause at the end of all statements.
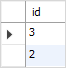
For example, the following statement applies the INTERSECT operator to the A and B tables and sorts the combined result set by the id column in descending order.
SELECTidFROM
a
INTERSECTSELECTidFROM
b
ORDERBYidDESC;
Besides the UNION, UNION ALL, and INTERSECT operators, SQL provides us with the MINUS operator that allows you to subtract one result set from another result set.
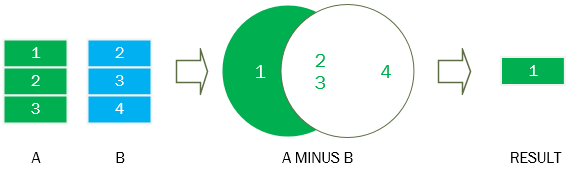
To use the MINUS operator, you write individual SELECT statements and place the MINUS operator between them. The MINUS operator returns the unique rows produced by the first query but not by the second one.
The following picture illustrates the MINUS operator.
To make the result set, the database system performs two queries and subtracts the result set of the first query from the second one.
In order to use the MINUS operator, the columns in the SELECT clauses must match in number and must have the same or, at least, convertible data type.
We often use the MINUS operator in ETL. An ETL is a software component in data warehouse system. ETL stands for Extract, Transform, and Load. ETL is responsible for loading data from the source systems into the data warehouse system.
After complete loading data, we can use the MINUS operator to make sure that the data has been loaded fully by subtracting data in target system from the data in the source system.
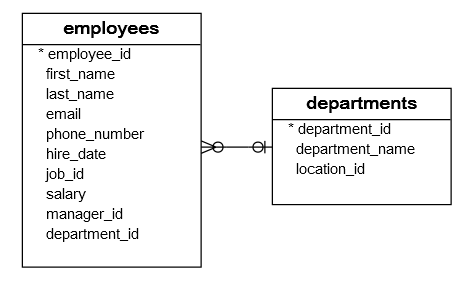
Each employee has zero or more dependents while each dependent depends on one and only one employees. The relationship between the dependents and employees is the one-to-many relationship.
The employee_id column in the dependents table references to the employee_id column in the employees table.
You can use the MINUS operator to find the employees who do not have any dependents. To do this, you subtract the employee_id result set in the employees table from the employee_id result set in the dependents table.
The following query illustrates the idea:
SELECT
employee_id
FROM
employees
MINUSSELECT
employee_id
FROM
dependents;
SQL MINUS with ORDER BY example
To sort the result set returned by the MINUS operator, you place the ORDER BY clause at the end of the last SELECT statement.
For example, to sort the employees who do not have any dependents, you use the following query:
SELECT
employee_id
FROM
employees
MINUSSELECT
employee_id
FROM
dependents
ORDERBY employee_id;
Save and discard changes with the COMMIT and ROLLBACK statements Explain read consistency
Other Schema Objects
Create a simple and complex view
Retrieve data from views
Introduction to the SQL Views
A relational database consists of multiple related tables e.g., employees, departments, jobs, etc. When you want to see the data of these tables, you use the SELECT statement with JOIN or UNION clauses.
SQL provides you with another way to see the data is by using the views. A view is like a virtual table produced by executing a query. The relational database management system (RDBMS) stores a view as a named SELECT in the database catalog.
Whenever you issue a SELECT statement that contains a view name, the RDBMS executes the view-defining query to create the virtual table. That virtual table then is used as the source table of the query.
Why do you need to use the views
Views allow you to store complex queries in the database. For example, instead of issuing a complex SQL query each time you want to see the data, you just need to issue a simple query as follows:
Views help you pack the data for a specific group of users. For example, you can create a view of salary data for the employees for Finance department.
Views help maintain database security. Rather than give the users access to database tables, you create a view to revealing only necessary data and grant the users to access to the view.
Creating SQL views
To create a view, you use the CREATE VIEW statement as follows:
First, specify the name of the view after the CREATE VIEW clause.
Second, construct a SELECT statement to query data from multiple tables.
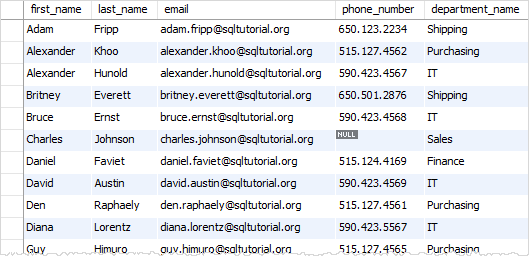
For example, the following statement creates the employee contacts view based on the data of the employees and departments tables.
CREATEVIEW employee_contacts ASSELECT
first_name, last_name, email, phone_number, department_name
FROM
employees e
INNERJOIN
departments d ON d.department_id = e.department_id
ORDERBY first_name;
By default, the names of columns of the view are the same as column specified in the SELECT statement. If you want to rename the columns in the view, you include the new column names after the CREATE VIEW clause as follows:
The DROP VIEW statement deletes the view only, not the base tables.
For example, to remove the payroll view, you use the following statement:
DROPVIEW payroll;
Create and maintain indexes
Why SQL Index?
The following reasons tell why Index is necessary in SQL:
SQL Indexes can search the information of the large database quickly.
This concept is a quick process for those columns, including different values.
This data structure sorts the data values of columns (fields) either in ascending or descending order. And then, it assigns the entry for each value.
Each Index table contains only two columns. The first column is row_id, and the other is indexed-column.
When indexes are used with smaller tables, the performance of the index may not be recognized.
Create an INDEX
In SQL, we can easily create the Index using the following CREATE Statement:
CREATEINDEX Index_Name ON Table_Name ( Column_Name);
Here, Index_Name is the name of that index that we want to create, and Table_Name is the name of the table on which the index is to be created. The Column_Name represents the name of the column on which index is to be applied.
CREATEINDEX index_state ON Employee (Emp_State);
Suppose we want to create an index on the combination of the Emp_city and the Emp_State column of the above Employee table. For this, we have to use the following query:
CREATEINDEX index_city_State ON Employee (Emp_City, Emp_State);
Create UNIQUE INDEX
Unique Index is the same as the Primary key in SQL. The unique index does not allow selecting those columns which contain duplicate values.
This index is the best way to maintain the data integrity of the SQL tables.
Syntax for creating the Unique Index is as follows:
CREATEUNIQUEINDEX Index_Name ON Table_Name ( Column_Name);
Introduction to SQL Server clustered indexes
The following statement creates a new table named production.parts that consists of two columns part_id and part_name:
The production.parts table does not have a primary key. Therefore SQL Server stores its rows in an unordered structure called a heap.
When you query data from the production.parts table, the query optimizer needs to scan the whole table to search.
For example, the following SELECT statement finds the part with id 5:
SELECT
part_id,
part_name
FROM
production.parts
WHERE
part_id = 5;
If you display the estimated execution plan in SQL Server Management Studio, you’ll see how SQL Server come up with the following query plan:
Note that to display the estimated execution plan in SQL Server Management Studio, you click the Display Estimated Execution Plan button or select the query and press the keyboard shortcut Ctrl+L:
Because the production.parts table has only five rows, the query executes very fast. However, if the table contains a large number of rows, it’ll take a lot of time and resources to search for data.
To resolve this issue, SQL Server provides a dedicated structure to speed up the retrieval of rows from a table called index.
SQL Server has two types of indexes: clustered index and non-clustered index. We will focus on the clustered index in this tutorial.
A clustered index stores data rows in a sorted structure based on its key values. Each table has only one clustered index because data rows can be only sorted in one order. A table that has a clustered index is called a clustered table.
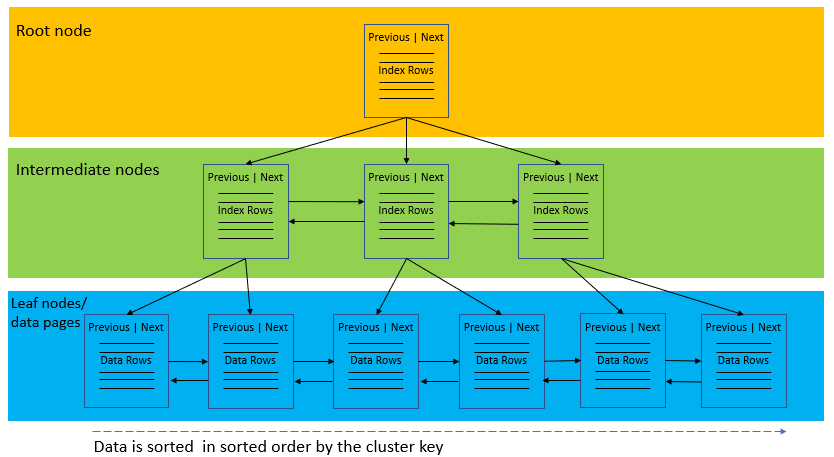
The following picture illustrates the structure of a clustered index:
A clustered index organizes data using a special structured so-called B-tree (or balanced tree) which enables searches, inserts, updates and deletes in logarithmic amortized time.
In this structure, the top node of the B-tree is called the root node. The nodes at the bottom level are called the leaf nodes. Any index levels between the root and the leaf nodes are known as intermediate levels.
In the B-Tree, the root node and intermediate level nodes contain index pages that hold index rows. The leaf nodes contain the data pages of the underlying table. The pages in each level of the index are linked using another structure called a doubly-linked list.
SQL Server Clustered Index and Primary key constraint
When you create a table with a primary key, SQL Server automatically creates a corresponding clustered index that includes primary key columns.
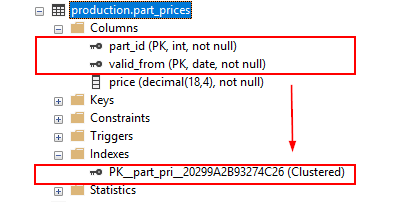
This statement creates a new table named production.part_prices with a primary key that includes two columns: part_id and valid_from.
If you add a primary key constraint to an existing table that already has a clustered index, SQL Server will enforce the primary key using a non-clustered index:
This statement defines a primary key for the production.parts table:
ALTERTABLEproduction.partsADDPRIMARYKEY(part_id);
Code language:CSS(css)
SQL Server created a non-clustered index for the primary key.
Using SQL Server CREATE CLUSTERED INDEX statement to create a clustered index.
When a table does not have a primary key, which is very rare, you can use the CREATE CLUSTERED INDEX statement to add a clustered index to it.
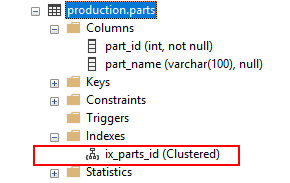
The following statement creates a clustered index for the production.parts table:
If you open the Indexes node under the table name, you will see the new index name ix_parts_id with type Clustered.
When executing the following statement, SQL Server traverses the index (Clustered Index Seek) to locate the rows, which is faster than scanning the whole table.
SELECT
part_id,
part_name
FROM
production.parts
WHERE
part_id = 5;
Table Variable
A Table Variable is a variable that can store the complete table of the data inside it. It is similar to a Table Variable but as I said a Table Variable is a variable. So how do we declare a variable in SQL? Using the @ symbol. The same is true for a Table Variable. so the syntax of the Table Variable is as follows:
Declare @TempTable TABLE(
id int,
Namevarchar(20)
)
insertinto @TempTable values(1,'Sourabh Somani')
insertinto @TempTable values(2,'Shaili Dashora')
insertinto @TempTable values(3,'Divya Sharma')
insertinto @TempTable values(4,'Swati Soni')
Select * from @TempTable
Difference between temporary tables and Table Variable
There are a difference between temporary tables and temporary variables, it is:
A Table Variable is not available after execution of the complete query so you cannot run a single query but a temporary table is available after executing the query.
For example:
A Transaction (Commit and Rollback) operation is not possible in a Table Variable but in a temporary table we can perform transactiona (Commit and Rollback).
For example:
Declare @TempTable TABLE(
id int,
Namevarchar(20)
)
begin tran T
insertinto @TempTable values(1,'Sourabh Somani')
insertinto @TempTable values(2,'Shaili Dashora')
insertinto @TempTable values(3,'Divya Sharma')
insertinto @TempTable values(4,'Swati Soni')
commit tran T
Select * from @TempTable
or
Declare @TempTable TABLE(
id int,
Namevarchar(20)
)
begin tran T
insertinto @TempTable values(1,'Sourabh Somani')
insertinto @TempTable values(2,'Shaili Dashora')
insertinto @TempTable values(3,'Divya Sharma')
insertinto @TempTable values(4,'Swati Soni')
rollback tran T
Select * from @TempTable
Important Points about Table Variables
The same as a temporary table.
Single query cannot be executed.
When we want to perform a few operations then use a Table Variable otherwise if it is a huge amount of data operation then use a temporary table.
Commit and Rollback (Transaction) cannot be possible with Table Variables so if you want to perform a transaction operation then always go with temporary tables.
What are scalar functions
SQL Server scalar function takes one or more parameters and returns a single value.
The scalar functions help you simplify your code. For example, you may have a complex calculation that appears in many queries. Instead of including the formula in every query, you can create a scalar function that encapsulates the formula and uses it in each query.
Creating a scalar function
To create a scalar function, you use the CREATE FUNCTION statement as follows:
First, specify the name of the function after the CREATE FUNCTION keywords. The schema name is optional. If you don’t explicitly specify it, SQL Server uses dbo by default.
Second, specify a list of parameters surrounded by parentheses after the function name.
Third, specify the data type of the return value in the RETURNS statement.
Finally, include a RETURN statement to return a value inside the body of the function.
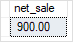
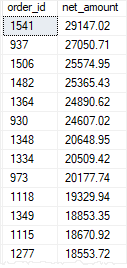
The following example creates a function that calculates the net sales based on the quantity, list price, and discount:
The following are some key takeaway of the scalar functions:
Scalar functions can be used almost anywhere in T-SQL statements.
Scalar functions accept one or more parameters but return only one value, therefore, they must include a RETURN statement.
Scalar functions can use logic such as IF blocks or WHILE loops.
Scalar functions cannot update data. They can access data but this is not a good practice.
Scalar functions can call other functions
What is a table-valued function in SQL Server
A table-valued function is a user-defined function that returns data of a table type. The return type of a table-valued function is a table, therefore, you can use the table-valued function just like you would use a table.
Creating a table-valued function
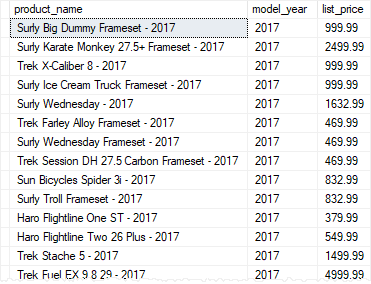
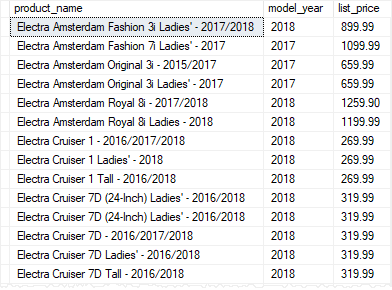
The following statement example creates a table-valued function that returns a list of products including product name, model year and the list price for a specific model year:
CREATEFUNCTION udfProductInYear (
@model_year INT
)
RETURNSTABLEASRETURNSELECT
product_name,
model_year,
list_price
FROM
production.products
WHERE
model_year = @model_year;
The syntax is similar to the one that creates a user-defined function.
The RETURNS TABLE specifies that the function will return a table. As you can see, there is no BEGIN...END statement. The statement simply queries data from the production.products table.
The udfProductInYear function accepts one parameter named @model_year of type INT. It returns the products whose model years equal @model_year parameter.
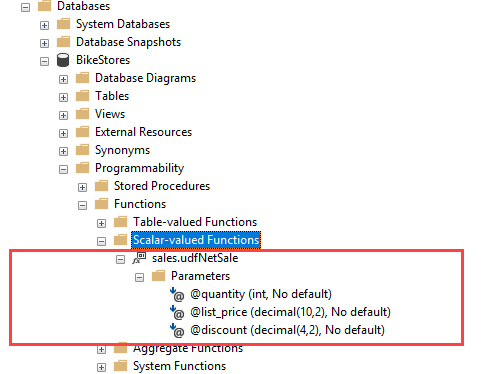
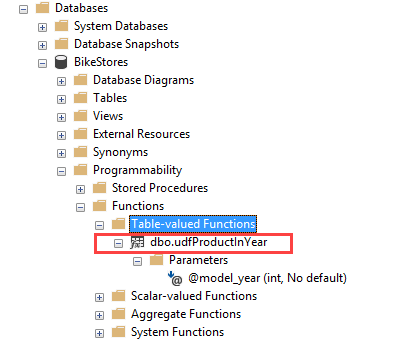
Once the table-valued function is created, you can find it under Programmability > Functions > Table-valued Functions as shown in the following picture:
The function above returns the result set of a single SELECT statement, therefore, it is also known as an inline table-valued function.
Executing a table-valued function
To execute a table-valued function, you use it in the FROM clause of the SELECT statement:
To modify a table-valued function, you use the ALTER instead of CREATE keyword. The rest of the script is the same.
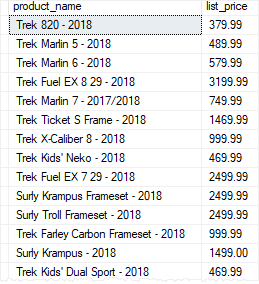
For example, the following statement modifies the udfProductInYear by changing the existing parameter and adding one more parameter:
ALTERFUNCTION udfProductInYear (
@start_year INT,
@end_year INT
)
RETURNSTABLEASRETURNSELECT
product_name,
model_year,
list_price
FROM
production.products
WHERE
model_year BETWEEN @start_year AND @end_year
Create an External Table by Using ORACLE_LOADER and by Using ORACLE_DATAPUMP Query External Tables
Manage Objects with Data Dictionary Views
Explain the data dictionary
Use the Dictionary Views
USER_OBJECTS and ALL_OBJECTS Views
Table and Column Information
Query the dictionary views for constraint information
Query the dictionary views for view, sequence, index, and synonym information Add a comment to a table
Query the dictionary views for comment information
Manipulate Large Data Sets
Use Subqueries to Manipulate Data
Retrieve Data Using a Subquery as Source
Insert Using a Subquery as a Target
Usage of the WITH CHECK OPTION Keyword on DML Statements List the types of Multitable INSERT Statements
Use Multitable INSERT Statements
Merge rows in a table
Track Changes in Data over a period of time
---------
Create, maintain, and use sequences
Create private and public synonyms
Control User Access
Differentiate system privileges from object privileges Create Users
Grant System Privileges
Create and Grant Privileges to a Role
Change Your Password
Grant Object Privileges
How to pass on privileges?
Revoke Object Privileges
------------
Data Management in Different Time Zones
Time Zones
CURRENT_DATE, CURRENT_TIMESTAMP, and LOCALTIMESTAMP þÿCompare Date and Time in a Session s Time Zone DBTIMEZONE and SESSIONTIMEZONE
Difference between DATE and TIMESTAMP
INTERVAL Data Types
Use EXTRACT, TZ_OFFSET, and FROM_TZ
Invoke TO_TIMESTAMP,TO_YMINTERVAL and TO_DSINTERVAL
Retrieve Data Using Sub-queries
Multiple-Column Subqueries
Pairwise and Nonpairwise Comparison
Scalar Subquery Expressions
Solve problems with Correlated Subqueries
Update and Delete Rows Using Correlated Subqueries The EXISTS and NOT EXISTS operators
Invoke the WITH clause
The Recursive WITH clause
Regular Expression Support
Use the Regular Expressions Functions and Conditions in SQL Use Meta Characters with Regular Expressions
Perform a Basic Search using the REGEXP_LIKE function Find patterns using the REGEXP_INSTR function Extract Substrings using the REGEXP_SUBSTR function Replace Patterns Using the REGEXP_REPLACE function Usage of Sub-Expressions with Regular Expression Support











Comments
Post a Comment